当大多数人还在享受新年假期时,梁文锋和他的团队已经在2025年最后一晚向学术界提交了一份“新年贺礼”,这篇论文可能预示着一场AI界的春节巨变。
2026年1月1日,当全国人民还沉浸在新年氛围中时,DeepSeek创始人梁文锋与团队在预印本平台发布了一篇重磅论文。论文题为《Manifold-Constrained Hyper-Connections》,提出了一种能稳定训练并提升大模型可扩展性的残差连接方案。
就在这篇技术论文公开的几天前,社交媒体上关于“DeepSeek V4.0即将发布”的讨论再次升温。一些观察敏锐的业内人士已经开始猜测,这篇论文的发布时间点可能暗示着重大版本更新即将到来。
## 新架构
梁文锋的这篇最新论文聚焦于解决大模型训练中的一个核心难题——稳定性与性能的平衡。
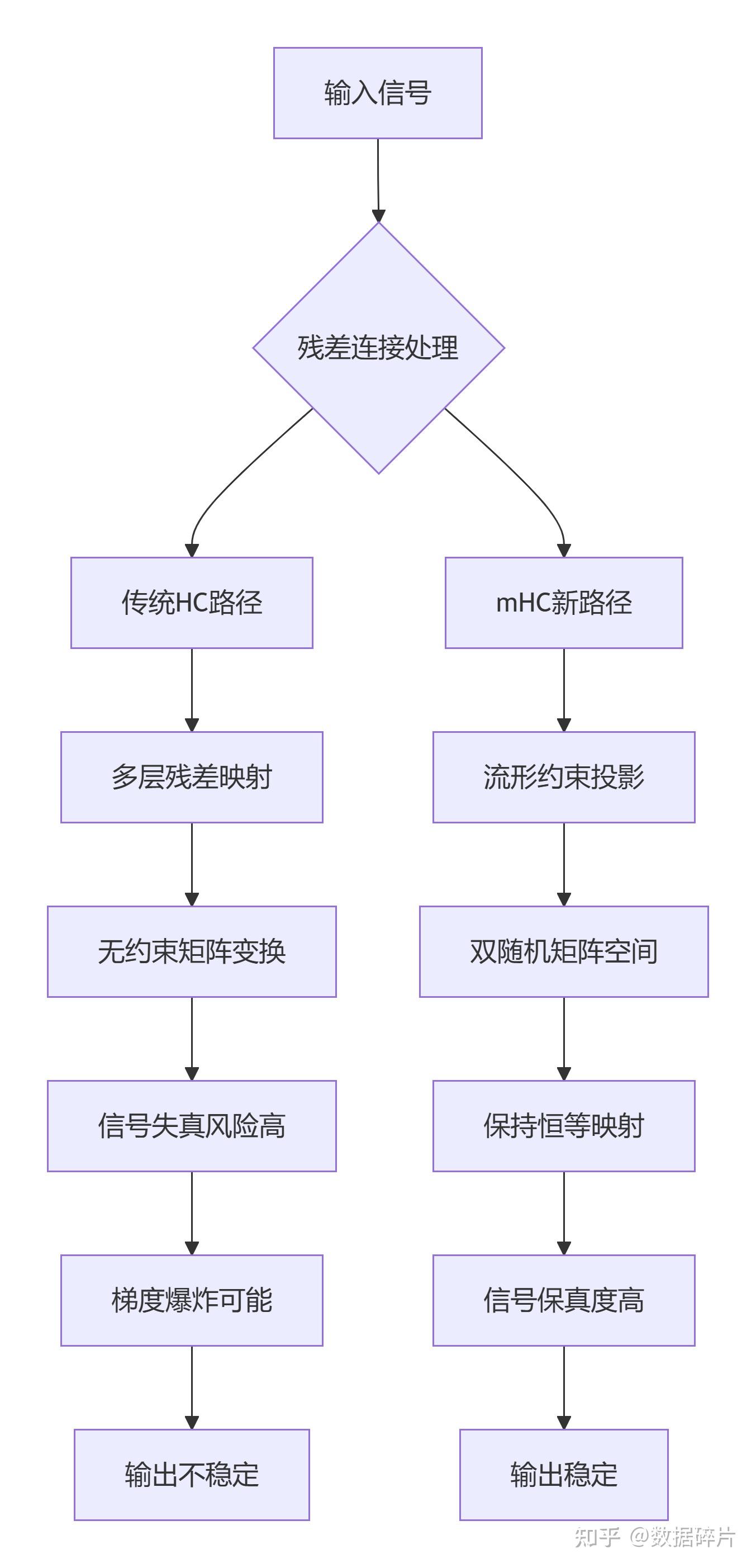
论文中提出的mHC(流形约束超连接)方案,直指当前大模型训练中的痛点。传统Hyper-Connections虽然能带来性能提升,但由于结构复杂且缺乏约束,常导致训练不稳定、信号失真甚至梯度爆炸等问题。
实验数据显示,在27B参数的模型中,传统HC的多层残差映射在反向传播中导致信号最大放大倍数逼近3000,存在明显梯度爆炸风险。这好比一条信息高速公路没有限速标志,车辆可能失控。
mHC方案通过将HC中的残差映射矩阵投影到双随机矩阵构成的“流形空间”,在保留拓扑表达力的同时,恢复原始残差连接的恒等映射性质。这一创新相当于为神经网络的“学习过程”划定了一个安全的操场,既允许自由探索,又确保不会失控“跑飞”。
传统HC与mHC架构对比示意图
## 突破性
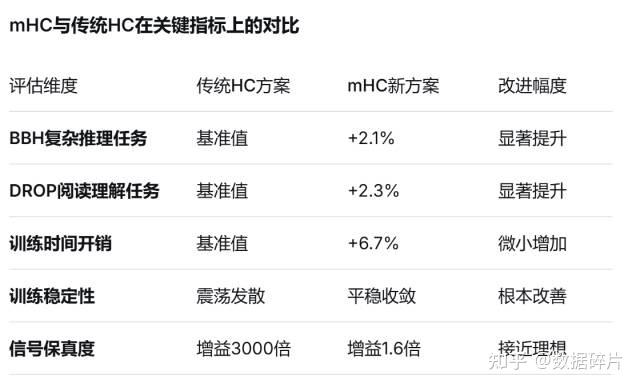
实验结果验证了mHC的突破性价值。在27B参数规模的测试中,mHC在8个下游任务上全面超越传统HC。
特别是在BBH(+2.1%)和DROP(+2.3%)等复杂推理任务上表现突出。更关键的是,mHC仅引入6.7%的训练时间开销,就实现了这种稳定性和性能的双重提升。
训练稳定性方面对比更加明显。mHC训练中损失平稳收敛,梯度稳定;而传统HC训练中损失震荡发散,梯度爆炸。
信号保真度的改善是另一个重要亮点。分析表明传统HC的复合映射增益高达3000,而mHC控制在1.6,接近理想恒等映射。
这意味着同样规模的计算资源,使用新架构的模型可以获得更好的效果,这个突破对下一代大规模模型的训练至关重要。
**训练稳定性对比图**
传统HC训练过程
损失值: ▁▂▃▄▅▆▇█▇▆▅▄▃▂▁ (剧烈震荡)
梯度: ████████████████ (频繁爆炸)
mHC训练过程
损失值: ▁▁▂▂▃▃▄▄▅▅▆▆▇▇██ (平稳收敛)
梯度: ▁▁▂▂▃▃▄▄▅▅▆▆▇▇██ (稳定可控)
## 信号
DeepSeek选择在新年第一天发布这篇论文,时机选择绝非偶然。回顾DeepSeek的发布历史,重大节日前发布新模型几乎是公司的传统。
2025年春节期间,DeepSeek R1模型引爆全网,用户量迅速突破2200万,成为现象级AI产品。
今年国庆前夕,DeepSeek也曾发布V3.2-Exp模型,作为“探索新技术用”的过渡版本。这一模式表明,DeepSeek倾向于在重要时间节点推出具有象征意义的产品。
**DeepSeek重要版本发布时间线**
2024年12月: DeepSeek V2发布
↓
2025年2月(春节): DeepSeek R1引爆,用户破2200万
↓
2025年9月: V3.2-Exp国庆前发布
↓
2025年12月1日: V3.2正式版发布,达GPT-5水平
↓
2026年1月1日: 梁文锋新论文公布
↓
2026年春节(预测): V4.0可能发布时间点
值得注意的是,2025年12月1日,DeepSeek同时发布了两个正式版模型:DeepSeek-V3.2和DeepSeek-V3.2-Speciale。
这两个模型已经展现出强大实力——在公开的推理类Benchmark测试中,DeepSeek-V3.2达到了GPT-5的水平,仅略低于Gemini-3.0-Pro。
## 猜测
关于DeepSeek V4.0的发布时间,业界一直有各种猜测。早在2025年9月,就有消息称V4将于10月发布,并将带来100万上下文、GRPO驱动推理及NSA/SPCT等前沿技术。
传闻还称V4将全面用国产AI芯片训练,与国产芯片全面适配。不过这些消息来源并非官方,需要谨慎对待。
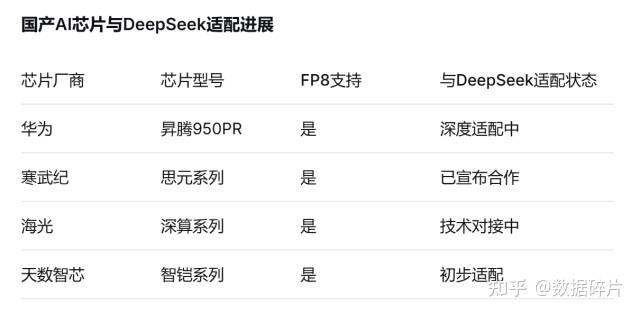
一个合理的推测是,DeepSeek V4.0的发布需要一个重要契机——与国产算力芯片的全面适配。这一点DeepSeek官方此前已经明确表示,下一代模型将支持FP8算法,与国产芯片全面适配。
目前国产AI芯片如华为昇腾、寒武纪、海光等都已宣布支持FP8算法。特别是华为昇腾950PR预计将支持FP8和FP4格式,算力达到1PFLOPS(FP8)/2PFLOPS(FP4)。
从这个角度看,DeepSeek V4.0的发布很可能会与国产芯片的重要进展同步。而春节作为中国人最重要的传统节日,无疑是展示这一里程碑的绝佳时机。
## 技术衔接
梁文锋新论文中提出的mHC架构,很可能正是DeepSeek V4.0的核心技术基础之一。
论文结论明确指出:“mHC或将有助于突破当前限制,并可能为下一代基础架构的演进指明新方向。” 这句话几乎可以视为对V4.0技术路线的暗示。
事实上,DeepSeek团队近年来一直在核心技术上进行突破性探索。2025年3月,团队发布了关于“原生稀疏注意力”的研究,让AI学会像人类一样“快速阅读”,在处理长文本时训练速度提升了6-9倍。
2025年9月发布的DeepSeek Sparse Attention技术,首次实现了细粒度稀疏注意力机制,在几乎不影响模型输出效果的前提下,大幅提升了长文本训练和推理效率。
DeepSeek技术演进路径
2025年3月: 原生稀疏注意力研究
⇓ 训练速度提升6-9倍
2025年9月: 细粒度稀疏注意力技术
⇓ 长文本处理效率大幅提升
2026年1月: mHC流形约束超连接
⇓ 训练稳定性根本改善
⇓
预测: V4.0技术矩阵整合
⇓
超稳定训练 + 超高效率 + 超强性能
这些技术突破与mHC架构的结合,很可能构成DeepSeek V4.0的技术矩阵。梁文锋在论文中展示的不只是单一技术改进,更是一种构建更强大、更稳定大模型的方法论。
## 结语
杭州,DeepSeek办公室的灯光在2025年最后一夜依然明亮。梁文锋和他的团队在提交完那篇关于流形约束超连接的论文后,或许已经开始调试下一个重大版本的代码。
2025年12月1日发布的DeepSeek-V3.2已经达到了GPT-5水平。而梁文锋最新论文中描述的mHC架构,为信号在神经网络中流动划定了“安全的操场”。
春节的烟花可能会与新一代AI模型的代码同时点亮夜空。当千万家庭团聚时,一款可能改变中国AI格局的产品或许正在悄然上线。
有Claude、ChatGPT、Gemini、Qwen、Doubao、Kimi、GLM等国内外大模型API调用,以及阿里云、华为云优惠需求的朋友,欢迎添加微信:gezicloud
社区交流欢迎关注:
微信公众号:AI创业云伙伴
知乎:AI创业云伙伴