1 月 13 日凌晨,DeepSeek 在 GitHub 悄悄上传了一篇论文,署名梁文锋。
这篇《Conditional Memory via Scalable Lookup》不是普通的技术更新——它直指 AI 行业的命门:算力成本。
论文核心是"Engram 条件记忆模块",一个颠覆性的想法:让 CPU 接手 GPU 的"记忆存储"工作,GPU 专心"动脑子" 。

数据很吓人:以前需要 8 张英伟达 A100 显卡、硬件成本数十万美元才能运行的千亿参数模型,现在只需要 1 张消费级显卡 + 4 根 64GB 内存条,成本约 1200 美元。
部署成本直降 90% ,性能却反而不降反升——中文知识测试 CMMLU 提升 4 分,32k 长文本处理准确率从 84.2% 飙升至 97%。
一时间,"AI 普惠时代来临"的呼声四起。有媒体甚至放言:"小公司、个人开发者都能轻松用上顶尖大模型能力"。
但等等,把"硬件降本"等同于"创业者的云账单危机解除",这是一个危险的认知陷阱。
一、90% 降本,降的是什么?
先看清楚 DeepSeek V4 到底降了什么成本。
Engram 模块的本质:把大模型中 80% 的静态知识(语言语法、常识概念、代码模板、数学公式)从神经网络中抽离出来,整理成一个巨大的"知识嵌入表",存放在 CPU 内存中,完全不占用 GPU 显存。

这带来的成本下降是硬件采购成本,不是云服务运营成本。
举个例子:某律所想要搭建一个包含 500 万判例的法律咨询模型。以前用传统方案要么花几十万元买 GPU,要么每月支付高额 API 费用;现在用 V4 方案,只需一台高性能 CPU + 大内存的服务器,成本仅为原来的 1/20,准确率还能从 68% 提升到 89%。
但这有个前提:你得自己建机房、买设备、搞运维。
二、云账单的三个隐形陷阱
DeepSeek V4 确实降低了自建部署的门槛,但对于绝大多数 AI 创业者来说,云账单危机远未解除。问题出在三个地方:
陷阱 1:API 调用成本依然高企
如果你选择调用 DeepSeek 的 API 而不是自建部署,成本并没有想象中那么低。
以 DeepSeek V3 为例,优惠期结束后,调用价格已经调整为:每百万输入 tokens 2 元,每百万输出 tokens 8 元。
虽然比 OpenAI GPT-4o 的输入 2.5 美元、输出 10 美元便宜不少,但对于高并发应用来说,这依然是一笔不小的开支。
一个日活 10 万用户的 AI 应用,如果平均每个用户每天产生 1000 tokens 的交互,那么每月的 API 调用成本可能高达数十万元。
更关键的是,V4 的定价尚未公布。按照行业规律,新旗舰模型的价格大概率会高于 V3。
陷阱 2:推理成本才是真正的"吞金兽"
DeepSeek V4 的降本主要体现在部署环节,但 AI 应用的成本大头其实是推理成本——每次用户请求产生的计算费用。
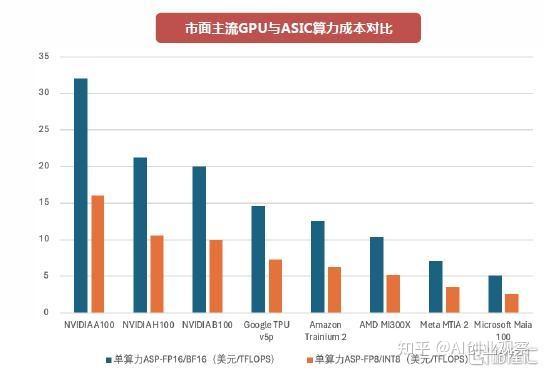
根据行业数据,GPU 云平台的价格范围通常是:
入门级训练 GPU(A10、RTX 4090、L4):0.50-1.20 美元/小时(专业服务商)、1.00-2.50 美元/小时(超大规模云厂商)
中端训练 GPU(A100 40GB/80GB):2.00-3.50 美元/小时(专业服务商)、3.00-5.00 美元/小时(超大规模云厂商)
高端训练 GPU(H100、H200):2.10-4.50 美元/小时(专业服务商)、4.00-8.00 美元/小时(超大规模云厂商)
即使 V4 能够降低对 GPU 算力的需求,推理成本的下降空间也有限。特别是对于需要实时响应的应用,GPU 依然是不可或缺的。
陷阱 3:65% 的成本在部署后
这是最容易被忽视的陷阱。
根据 Menlo Ventures 的最新数据,企业 AI 的自研与购买比例发生彻底倒挂:2024 年还有 47% 的企业坚持内部自研,到了 2025 年,这个数字骤降至 24%,而选择直接购买成熟方案的企业飙升至 76%。
原因很简单:技术债务和集成复杂性,让企业选择放弃自研转向购买。
数据显示,65% 的总成本发生在部署之后。每月高达 2 万美元的维护费、每年数万甚至十万美元的合规安全投入,这些隐形成本迅速吞噬了项目预算。
即使 DeepSeek V4 降低了部署门槛,运维、安全、合规、监控这些"隐形成本"依然存在。对于资源有限的创业公司来说,这些成本可能比硬件采购更致命。
三、算力民主化 ≠ 成本民主化
DeepSeek V4 确实实现了算力民主化——让更多人用得起大模型。但成本民主化还远远没有实现。
因为成本不只是硬件,还包括:






