全场景统一AI框架的挑战所谓全场景AI,是指可以将深度学习技术快速应用在云边端不同场景下的硬件设备上,包括云服务器、移动终端以及IoT设备等等,高效运行并能有效协同。
首先注册华为云账号,了解华为云AI框架MindSpore:
华为云AI注册链接
实名认证后,可以免费体验AI框架MindSpore。
全场景统一AI框架的挑战所谓全场景AI,是指可以将深度学习技术快速应用在云边端不同场景下的硬件设备上,包括云服务器、移动终端以及IoT设备等等,高效运行并能有效协同。对于框架而言,涉及三大挑战:快速部署、高效运行、端云协同。
如何将训练好的模型快速地部署到云服务器、移动终端以及各种IoT设备上进行推理甚至增量训练?
云服务器上推理通常以Service的方式进行部署,训练好的模型直接通过远程接口调用(gRPC/REST)推送到云服务器上,用户调用云推理服务接口进行推理。对于移动终端和IoT设备,由于硬件资源限制,云侧的模型和推理运行框架体积太大,无法直接部署,因此模型的压缩和运行框架的轻量化成为移动终端和IoT设备上部署的关键。
面向移动终端和IoT设备轻量化的挑战,提供独立的轻量化的端侧AI框架是比较好的解决方案,同时这样的轻量化框架可能还不止一种形态,比如类似于智能手机这些富终端和类似耳环这些瘦终端面临的挑战就不一样,富终端一般存储空间还是比较充裕的,有一定的算力;瘦终端的条件则要苛刻的多,底噪要求控制在百K级别,这样你就不能放一个运行时进去,同时还要考虑给AI开发者一个通用的解决方案。
有了轻量化的端侧框架以及好的模型压缩转换技术是否就可以实现快速部署的目的?其实还有问题,因为如果我们端侧的架构与云侧的架构是分离的、实现是不一致的,如模型的IR不同、算子的定义不同、推理的API接口不同,那很可能导致云侧训练的模型无法顺利的转换到端侧去执行,云侧的推理代码无法在端侧重用。
一般框架的从云侧训练模型到端侧部署的流程如下:

这种方式目前存在一些问题:第一个问题:两套模型定义很难保持一致,比如云侧和端侧的算子经常会出现一方缺失的问题,导致模型转换失败。
第二个问题:云和端都需要的功能会重复开发,并可能有不一致,比如为了提升推理性能而进行的fusion优化需要端云两边都做一遍,数据处理的不一致导致精度问题等。
第三个问题:云侧训练好的模型在端侧进行在线训练需要相对复杂的转换。
对于分离的端云框架的不一致问题,是否可以通过如ONNX这样的标准去解决?很难,原因在于,AI产业的快速发展,新的算子类型快速涌现,标准实际上很难跟得上,所以解决的途径还是应该着落在AI框架上。
全场景的高效运行,分解下来就是高效的算子、高效的运行时以及高效的模型,实现异构硬件的最大算力,提升AI算法的运行性能和能效比。
算子的性能,需要从算法和底层指令优化多个层面进行优化。比如卷积,Winograd算法相比于Im2Col+GEMM,在很多经典卷积神经网络上性能就有很好的性能提升。
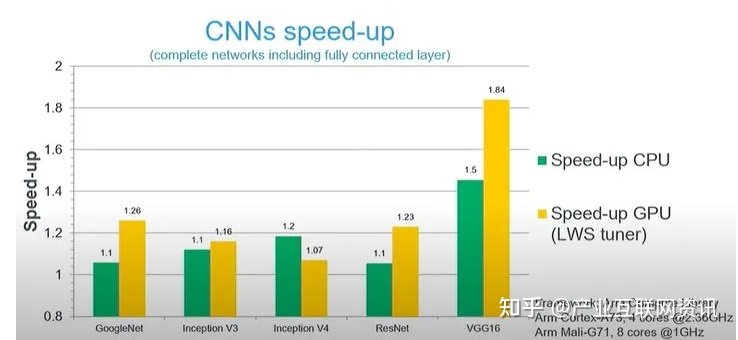
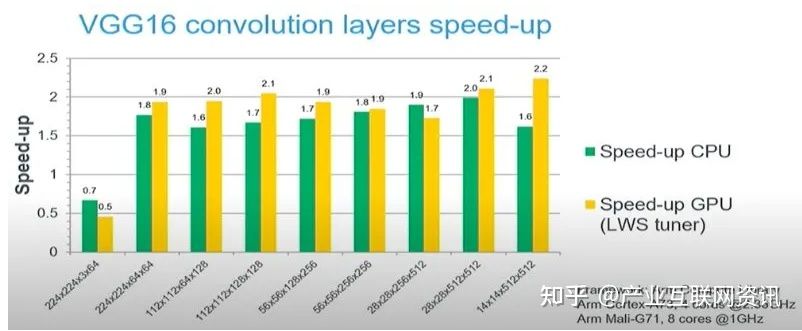
但是,并不是所有的场景下Winograd的算法都优于Im2Col+GEMM。在下面的图中,当shape为224x224x3x64时,Winograd的性能反而有所恶化。因此,在不同条件下选择最优的算法对性能至关重要。
算法层面的优化,更多的是通过减少运行时的计算次数(乘法)来提升性能,而指令层面的优化则是为了更充分的利用硬件的算力。对于CPU硬件,影响指令执行速度的关键因素包括了L1/L2缓存的命中率以及指令的流水,通用的优化方法有:
- 选择合理数据排布,如NHWC、NC4HW4等等
- 寄存器的合理分配,将寄存器按照用途,可以划分为feature map寄存器、权重寄存器和输出寄存器,寄存器的合理分配可以减少数据加载的次数。
- 数据的预存取,通过prefetch/preload等指令,可以提前将数据读到cache中。
- 指令重排,尽量减少指令的pipeline stall。
- 向量化计算,使用SIMD指令,如ARM NEON指令,X86 SSE/AVX指令等。
这些优化需要对硬件架构有深入的了解。
端侧运行时的性能主要面临异构和异步并行的挑战,从模型角度看,大部分模型在推理的时候看上去是串行执行的,不过如果把算子内部打开,变成细粒度的kernel,整体执行流还是一个dataflow的图,存在不少异步并行的机会,同时端侧存在大量的异构设备,如果一个模型在执行的时候使用多种类型的设备,中间也存在不同的流水线。
模型的性能,主要还是靠离线的优化和tuning,这一块业界也已经许多实践了,总的思路主要是规则化的融合pass和离线的算子tuning结合。
首先注册华为云账号,了解华为云AI框架MindSpore:
华为云AI注册链接
实名认证后,可以免费体验AI框架MindSpore。






